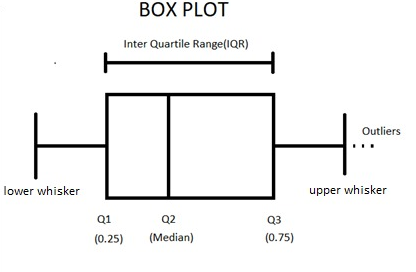
25th percentile of the data Q1. Outliers are identified as points with residuals larger than U or smaller than L.
What Are Outliers And How To Treat Them In Data Analytics Aquarela
Transformation of data and Binning the data also helps in controlling the effects of outliers in the data.

How to treat outliers in data. You can remove the top 1 and bottom 1 of values. The tukey formula uses quantiles to produce upper and lower range values beyond which all values are considered as outliers. Graphing Your Data to Identify Outliers Boxplots histograms and scatterplots can highlight outliers.
For non-seasonal time series outliers are. Youll get Q1 Q2 and Q3. Imputation with mean median mode.
Boxplots display asterisks or other symbols on the graph to indicate explicitly when datasets contain outliers. Create a box plot. One option is to try a transformation.
IQR Score method. We will use Z-score function defined in scipy library to detect the outliers. Please refer to the picture Outliers Scaling above.
These data points which are way too far from zero will be treated as the outliers. A natural part of the population you are studying you should not remove it. These graphs use the interquartile method with.
Once the outliers are identified and you have decided to make amends as per the nature of the problem you may consider one of the following approaches. The field of the individuals age Antony Smith certainly does not represent the age of 470 years. Data points Q3 15IQR and data points Q1 15IQR will be considered as outliers.
Df dfdfhp Upper_Whisker Outliers will be any points below Lower_Whisker or above Upper_Whisker. The following ways can be used to remove the outlier values from data. The second line prints the shape of this data which comes out to be 375 observations of 6 variables.
Check shape of data. The same formula is also used in a boxplot. The rule of thumb is that anything not in the range of Q1 - 15 IQR and Q3 15 IQR is an outlier and can be removed.
Square root and log transformations both pull in high numbers. Consider the below scenario where you have an outlier in the Salary column. The first argument is the array youd like to manipulate Column A and the second argument is by how much youd like to trim the upper and lower extremities.
The case of the following table clearly exemplifies a typing error that is input of the data. This method has been dealt with in detail in the discussion about treating missing values. In most of the cases a threshold of 3 or -3 is used ie if the Z-score value is greater than or less than 3 or -3 respectively that data point will be identified as outliers.
50th percentile of the data Q2. Not a part of the population you are studying ie unusual properties or conditions you can legitimately remove the outlier. However the above-mentioned methods are the most common methods for controlling the adverse effects of outliers.
The first line of code below removes outliers based on the IQR range and stores the result in the data frame df_out. Outliers can now be detected by determining where the observation lies in reference to the inner and outer fences. This is really easy to do in Excela simple TRIMMEAN function will do the trick.
Detect and treat outliers using python Using a Scatter plot graph Using Box plot graph Using Z_score method Normally distributed Data. 75th percentile of the data Q3. We have several solutions for imputing missing and outliers data and we will present two of them here.
This can make assumptions work better if the outlier is a dependent variable and can reduce the impact of a single point if the outlier is an independent variable. When you decide to remove outliers document the excluded data points and explain your reasoning. One way to account for this is simply to remove outliers or trim your data set to exclude as many as youd like.
The residuals are computed and the following bounds are computed. In which data has been divided into quartiles Q1 Q2 and Q3. Apply conditions to remove outliers.
Using tukey formula to identify outlier. Outlier on the upper side 3rd Quartile 15 IQR. If a single observation is more extreme than either of our outer fences then it is an outlier and more particularly referred to as a strong outlierIf our data value is between corresponding inner and outer fences then this value is a suspected outlier or a weak outlier.
Static imputation imputation by the mean or median for the quantitative. U q 09 2 q 09 q 01 L q 01 2 q 09 q 01 where q 01 and q 09 are the 10th and 90th percentiles of the residuals respectively. Outliers are treated by either deleting them or replacing the outlier values with a logical value as per business and similar data.
IQR is Interquartile Range. The simplest way to find outliers in your data is to look directly at the data table or worksheet the dataset as data scientists call it. Outlier on the lower side 1st Quartile 15 IQR.
Outlier Treatment With Python A Simple And Basic Guide To Dealing By Sangita Yemulwar Analytics Vidhya Medium

How To Use Spss Dealing With Outliers Youtube

How To Remove Outliers For Machine Learning By Anuganti Suresh Analytics Vidhya Medium

How To Handle Outliers In Data Analysis Multivariate Outlier Detection
How To Handle Outliers In Data Analysis Multivariate Outlier Detection

Knowing All About Outliers In Machine Learning

Outlier Treatment With Python A Simple And Basic Guide To Dealing By Sangita Yemulwar Analytics Vidhya Medium

10 How To Detect Outliers Data Science Beginners

What Are Outliers And How To Treat Them In Data Analytics Aquarela










0 comments:
Post a Comment