In most of the cases a threshold of 3 or -3 is used ie if the Z-score value is greater than or less than 3 or -3 respectively that data point will be identified as outliers. These data points which are way too far from zero will be treated as the outliers.

Anomaly Detection With Time Series Forecasting By Adithya Krishnan Towards Data Science
A temporal dataset with outliers have several characteristics.

How to treat outliers in time series data. STD Deviation of kids age in the given series. Time-series pandas numpy outlier seaborn. There is systematic pattern which is deterministic and some variation which is stochastic Only a few data points are outliers.
Transformation of data and Binning the data also helps in controlling the effects of outliers in the data. The simplest way to find outliers in your data is to look directly at the data table or worksheet the dataset as data scientists call it. A description of the procedure and the implementation is given in the documentation attached to the package.
Essentially instead of removing outliers from the data you change their values to something more representative of your data set. Decide how auto-correlative your usual event in the time series is. From scipy import stats znpabs statszscore dfhp print z Step 4.
The resulting time series of residuals can then have some basic statistics computed on it to find outliers for example any data points outside of 15 interquartile-range could be classified as an outlier. You may also see this post. 33598941782277745 The outlier in the dataset is Teenagers.
Its a small but important distinction. IQR tells us the variation in the data set. If a time series is plotted outliers are usually the unexpected spikes or dips of observations at given points in time.
I found one saying to c alculate the IQR interquantile range Q3 minus Q1 then multiply by 15 and adding the amount to Q3 and substracting that from Q1 lower limit. The R package tsoutliers implements the Chen and Liu procedure for detection of outliers in time series. I have plotted the data now how do I remove the values outside the range of the boxplot outliers.
Follow edited Jul 1 19 at 502. Check shape of data. However the above-mentioned methods are the most common methods for controlling the adverse effects of outliers.
The second line prints the shape of this data which comes out to be 375 observations of 6 variables. One way to do this is to find the mean μ and standard deviation σ of the Random time series data and set the anomaly detection as data points that fall outside 4 σ the mean. An easy way to do all this for an offline algorithm is to fit a polynomial or spline to the time series then compute the difference between your time series and the fitted polynomialspline.
Get the Z-score table. The case of the following table clearly exemplifies a typing error that is input of the data. For example Im tracking temperature over time and it rarely changes more than 30 degrees F in an hour.
We will use Z-score function defined in scipy library to detect the outliers. It may also be possible to apply an outlier robust methods of making valid. First we could just take the section of data after the last missing value assuming there is a long enough series of observations to produce meaningful forecasts.
The first line of code below removes outliers based on the IQR range and stores the result in the data frame df_out. The field of the individuals age Antony Smith certainly does not represent the age of 470 years. District date Variable1 I looked online to fine a solution to dealing with outliers.
Please refer to the picture Outliers Scaling above. Outliers are significantly different from the rest of the data. Any value which is beyond the range of -15 x IQR to 15 x IQR treated as.
When missing values cause errors there are at least two ways to handle the problem. When you trim data the extreme values are. We find the z-score for each of the data point in.
The Random time series can be used to create outlier detection rules for anomaly detection. In this method by using Inter Quartile Range IQR we detect outliers. Should you keep outliers remove them or change them to another variable.
15 IQR Score method. Since the presence of one or more outliers in a data set could lead to bias in the estimation of parameters of the model and greatly inflates the estimate of the variance σ 2 there is serious need to consider methods of removal of outliers from time series data. Throw out or smooth any values where the observed value changes more than that.
But I am not sure how to. All the AVG data is in a single column I need it for time series modelling. The R package forecast uses loess decomposition of time series to identify and replace outliers.
Much of the debate on how to deal with outliers in data comes down to the following question. 25th percentile of the data Q1. In which data has been divided into quartiles Q1 Q2 and Q3.
My data is a time series with multiple variables by districts. For seasonal time series the seasonal component from the STL fit is removed and the seasonally adjusted series is linearly interpolated to replace the outliers before re-seasonalizing the result. The rule of thumb is that anything not in the range of Q1 - 15 IQR and Q3 15 IQR is an outlier and can be removed.
For non-seasonal time series outliers are replaced by linear interpolation. 50th percentile of the data Q2.

Pin On Stats Ml

Understanding Outliers In Time Series Analysis Arcgis Pro Documentation

When Should You Delete Outliers From A Data Set Atlan Humans Of Data Principal Component Analysis Data Data Science

Anomaly Detection By Alignminds Anomaly Detection Anomaly Detection
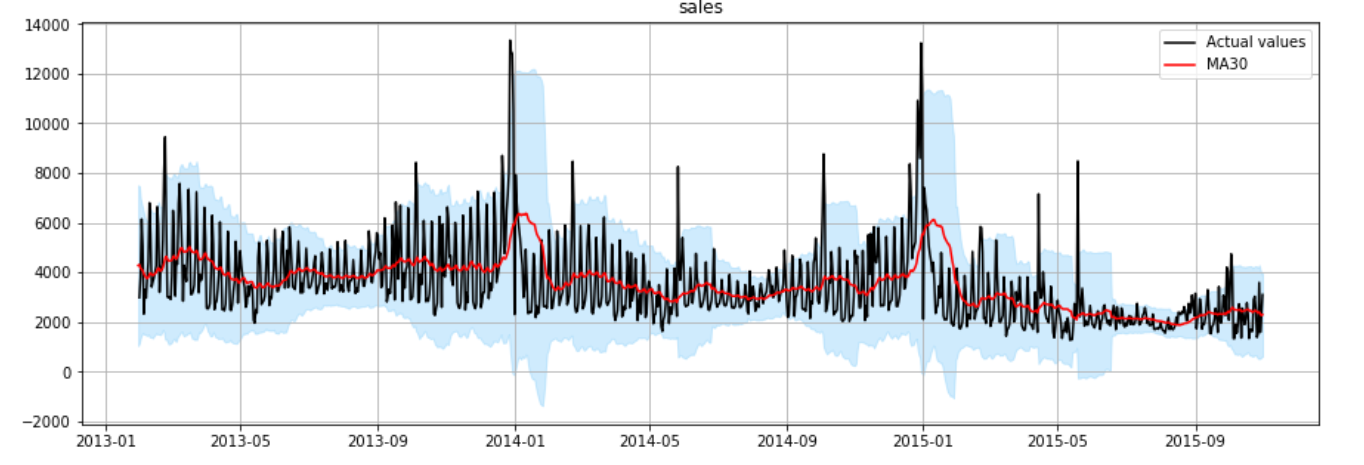
Time Series Analysis For Machine Learning By Mauro Di Pietro Towards Data Science
Time Series Anomaly Detection Algorithms By Pavel Tiunov Cube Dev

Understanding Outliers In Time Series Analysis Arcgis Pro Documentation
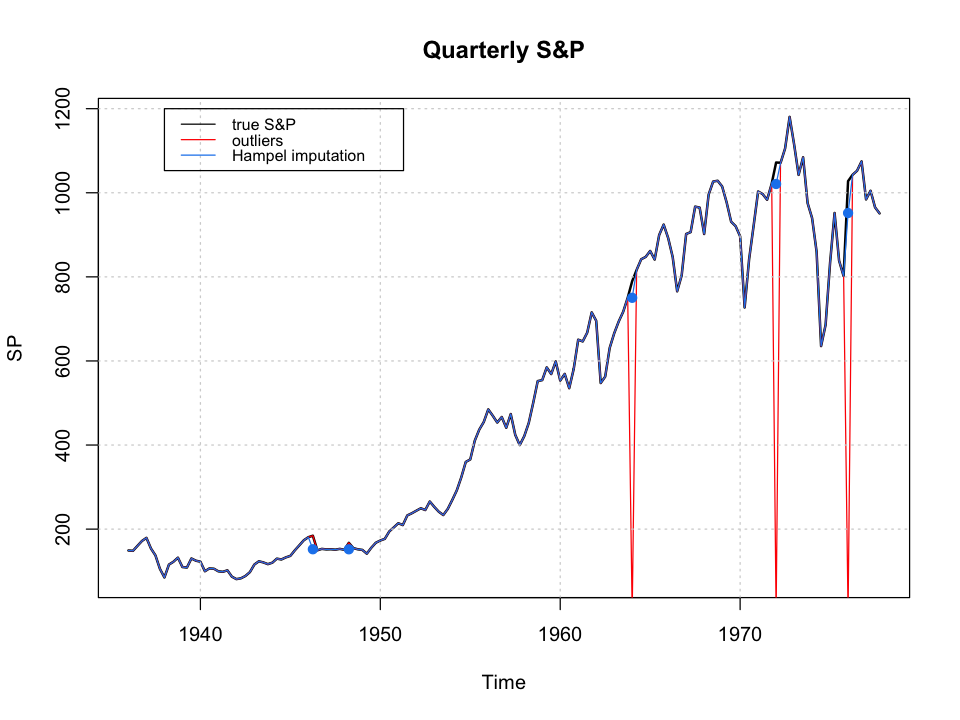
Clean Up Your Time Series Data With A Hampel Filter By Willie Wheeler Wwblog Medium
Pin On Data Science










0 comments:
Post a Comment