Outliers in time series. Instead automatic outlier detection methods can be used in the modeling pipeline and compared just like.
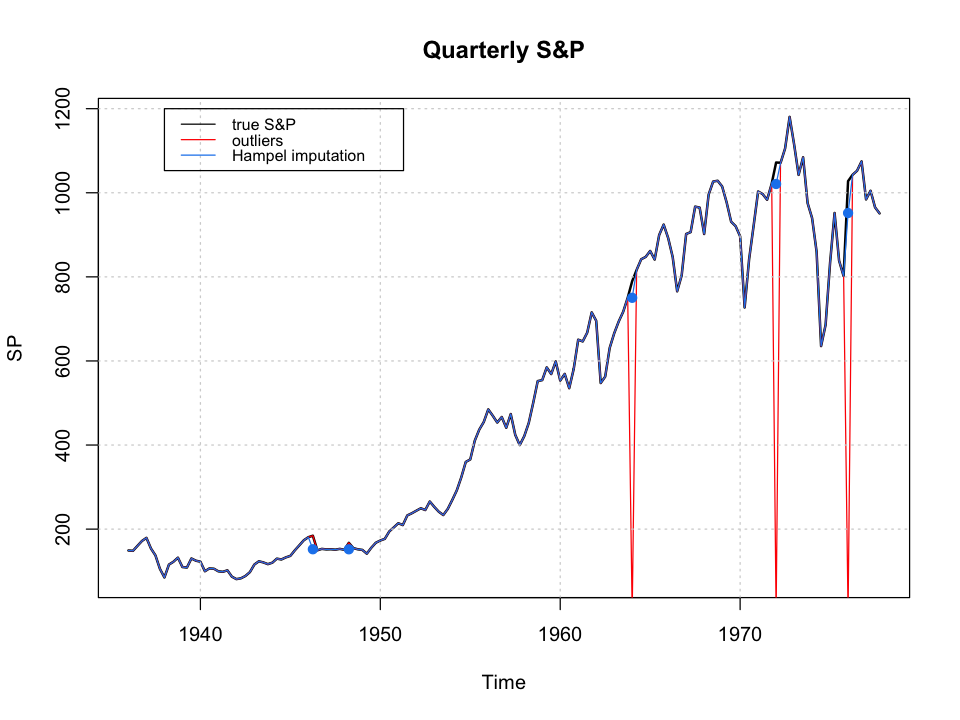
Clean Up Your Time Series Data With A Hampel Filter By Willie Wheeler Wwblog Medium
Sorteddatacolumn Q1Q3 nppercentiledatacolumn 2575 IQR Q3 Q1 lower_range Q1 15 IQR upper_range Q3 15 IQR return lower_range.
How to treat outliers in time series python. Decide how auto-correlative your usual event in the time series is. Hampel data This ones super straight forward and usually does the. Based on what Ive read so far the following methods can be applied.
1 printdf Q1 - 15 IQR df Q3 15 IQR python. Apply conditions to remove outliers. The above output prints the IQR scores which can be used to detect outliers.
What is the best way to treat outliers in a time series forecasting model. An easy way to do all this for an offline algorithm is to fit a polynomial or spline to the time series then compute the difference between your time series and the fitted polynomialspline. In terms of definition an outlier is an observation that significantly differs from other observations of the same feature.
Z i-meanstd if z threshold. Throw out or smooth any values where the observed value changes more than that. The presence of outliers in a classification or regression dataset can result in a poor fit and lower predictive modeling performance.
Youll use the output from the previous exercise percent change over time to detect the outliers. For example Im tracking temperature over time and it rarely changes more than 30 degrees F in an hour. There are two ways to remove outliers from time series data one is calculating percentilemean std-dev which I am thinking you are using the another way is looking at the graphs because sometimes data spread gives more information visually.
In this exercise youll handle outliers - data points that are so different from the rest of your data that you treat them differently from other normal-looking data points. If you have multiple columns in your dataframe and would like to remove all rows that have outliers in at least one column the following expression would do that in one shot. Import numpy as np from tsmoothieutils_func import sim_randomwalk from tsmoothiesmoother import LowessSmoother data df valuevaluesreshape 1 -1.
We can see that we have 4 outliers we can get them by. Using dummy variables to remove the effect of explainable spikes eg. It is a python library for time-series smoothing and outlier detection in a vectorized way.
Common is replacing the outliers on the upper side with 95 percentile value and outlier on the lower side with 5 percentile. Unlike trimming here we replace the outliers with other values. Where the rows are dates and the columns are values recorded by different sensors on those dates.
The code below generates an output with the True and False values. On the time series in the figure. If a time series is plotted outliers are usually the unexpected spikes or dips of observations at given points in time.
Df pdDataFrame nprandomrandn 100 3 from scipy import stats df npabs statszscore df 3all axis1. A temporal dataset with outliers have several characteristics. Identifying and removing outliers is challenging with simple statistical methods for most machine learning datasets given the large number of input variables.
Before working with the data for the purpose of predicting it I would like to remove the anomalies. Import numpy as np kids_age 1 2 4 8 3 8 11 15 12 6 6 3 6 7 129557101011131414 mean npmeanvoting_age std npstdvoting_age printMean of the kids age in the given series mean printSTD Deviation of kids age in the given series std threshold 3 outlier for i in voting_age. Here is one very simple function that you can use for removing them.
In particular for product demand modeling. Holiday dummy variables Identify and replace using Rs tsclean. Points where the values are True represent the presence of the outlier.
The resulting time series of residuals can then have some basic statistics computed on it to find outliers for example any data points outside of 15 interquartile-range could be classified as an outlier. Weve all dealt with outliers in our time series data. Df dfdfhp Upper_Whisker Outliers will be any points below Lower_Whisker or above Upper_Whisker.

Outlier Treatment With Python A Simple And Basic Guide To Dealing By Sangita Yemulwar Analytics Vidhya Medium

Pin On Stats Ml
How To Identify Outliers In A Time Series With Correlated Variables Cross Validated

When Should You Delete Outliers From A Data Set Atlan Humans Of Data Principal Component Analysis Data Data Science

How To Replace Outlier Data In Pandas Stack Overflow
Time Series Outlier Detection Data Science Stack Exchange

Simple Outlier Detection For Time Series Cross Validated
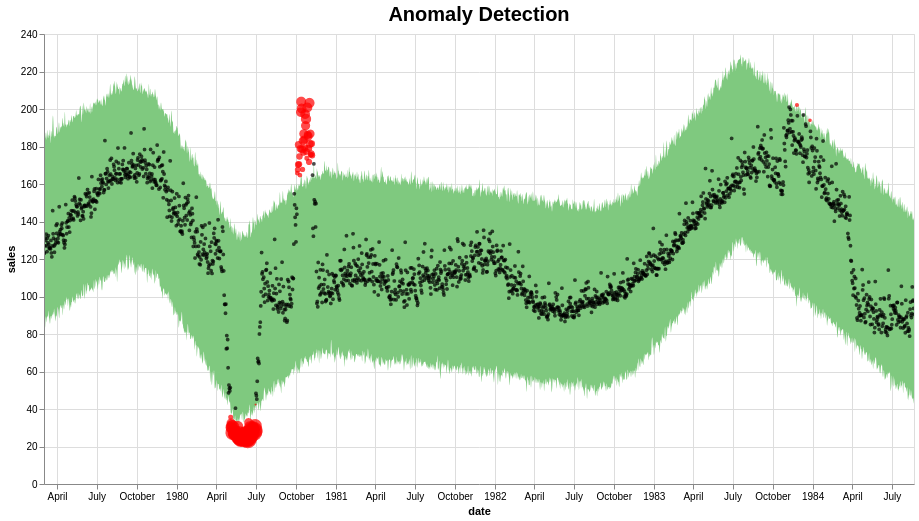
Anomaly Detection In Time Series With Prophet Library By Insaf Ashrapov Towards Data Science
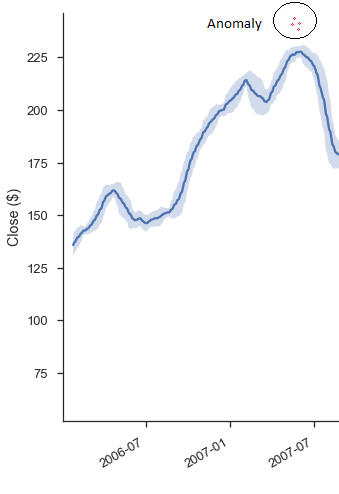
Anomaly Detection In Time Series With Prophet Library By Insaf Ashrapov Towards Data Science










0 comments:
Post a Comment